-
[6주차] Youtube 허민석 : 딥러닝 자연어처리 (2차)DSCstudyNLP 2020. 2. 19. 20:11
https://www.youtube.com/playlist?list=PLVNY1HnUlO26qqZznHVWAqjS1fWw0zqnT
딥러닝 자연어처리 - YouTube
www.youtube.com
https://sy-programmingstudy.tistory.com/13
[6주차] Youtube 허민석 : 딥러닝 자연어처리 (1차)
https://www.youtube.com/playlist?list=PLVNY1HnUlO26qqZznHVWAqjS1fWw0zqnT 딥러닝 자연어처리 - YouTube www.youtube.com 이 글은 Youtube 허민석님의 딥러닝 자연어처리 강의 목록 13개를 수강하고 정리한 1차..
sy-programmingstudy.tistory.com
이 글은 Youtube 허민석님의 딥러닝 자연어처리 강의 목록 13개를 수강하고 정리한 2차본입니다. 1차는 위 링크를 확인해주세요. 수식, 그래프 이미지의 출처는 강의 필기 캡처본입니다.
WMD 문서 유사도 구하기
WMD는 Word mover's distance의 줄임말이다. 최근에 문서 유사도 구하는 방법으로 상당히 각광받고 있다. 이 WMD는 Word2Vec을 근간으로 하고 있다. Word2Vec을 사용해서 단어 간의 유클리드 거리를 사용하는게 핵심이다.
What is Word2Vec?
Word2Vec의 특징을 알아보자.
- Word Embedding
- 유사도는 한 문장에서 그 단어의 이웃들로 인해 계산된다.
- 직접 만들지 않아도 된다. 이미 나와있는 Word Embed가 상당히 많다.
- GoogleNews-vectors-negative300.bin.gz가 가장 유명하다.
wmd에 앞서 word2vec에 대해 알아보자. 다음 두가지 문장이 있다.
- "king brave man"
- "queen beautiful woman"
각 단어별로 이웃들을 구할 수 있다. window size = 1이라고 할 때 다음 표와 같다.

(1) 이 단어들이 input으로 들어가고 neighbor들이 target으로 다음 그림과 같이 뉴런 네트워크에 들어가게 된다.
(2) output과 이웃의 값이 비교가 된 다음에
(3) back propagation으로 히든 레이어에 있는 w1과 w2가 최적화된다.
(4) 학습을 마치면 바로 히든 레이어에 있는 값이 Word2Vec이 된다.
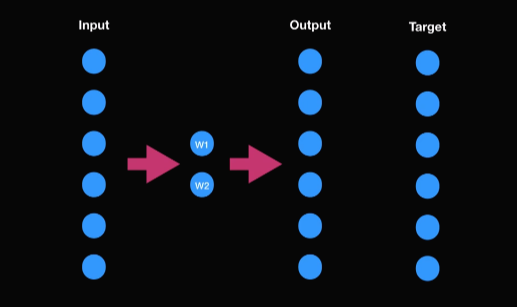



다음과 같이 w1, w2값을 받았다고 가정해보자. 2차원 데이터니까 다음과 같이 시각화 할 수 있다. 유사도가 비슷한 단어들은 서로 비슷한 위치에 있는 것을 확인할 수 있다. 또한 재미있는 계산도 할 수 있다. king에서 man을 빼고 woman을 더하면 queen이 된다. 이처럼 벡터 스페이스에 유사도가 존재하기 때문에 유클리드 거리를 사용해서 WMD에서 문서의 유사도를 구할 수 있다.

Word Mover's Distance(WMD)
WMD를 알아보자. 다음 세 문장이 있다.
- "prince fearless guy"
- "king brave man"
- "queen beautiful woman"
첫번째 문장은 man, brave, king 그룹과 woman, beautiful, queen그룹 중에서 어느 곳에 더 가까울까? prince, fearless, guy는 king, brave, man그룹과 단어가 더 가까이 위치해 있다. 즉, 문서의 유사도가 더 높다.

WMD document repressentation
WMD의 핵심 알고리즘을 간단하게 보자. 4개의 문장이 있다.
- D0 : The president greets the press in Cicago
- D1 : Obama speaks to the media in Illinois
- D2 : THe band gave a concert in Japan
- D3 : Obama speaks in Illinois
i) 먼저 알아야 할 것은 Nomalized Bag of Words after stop words removal이다. stop words를 없앤다. 그리고 nomalized bag of words를 한다. d0의 경우 4개의 단어로 이루어져 있는데 president가 1번 출현해서 0.25의 값을 갖는다. d3의 경우 총 3개의 단어가 있는데 오바마가 한번 등장했으니까 이 값은 0.33의 값을 갖는다. 실제 0이란 값은 사용하지 않으므로 최종적으로 다음과 같이 표현 가능하다.

remove stop words 

nomalized bag of words 그렇다면 이 값들이 의미하는 것은 무엇일까? 단어의 함유량을 의미한다. 문장이 하나 주어졌을 때 단어가 얼마정도 함유되어 있느냐 즉 이 문장을 다른 문장으로 옮길 경우에는 이만큼을 우리가 옮겨야한다는 개념이다. 예제를 통해 자세히 알아보자.

위 그래프에서 파란색 점들이 d1이고 녹색 점들이 d0이다. 오바마랑 가까운 녹색점은 president이다. 오바마와 president사이의 유클리드 거리를 구하면 0.25이다. 이때 단순히 유클리드 거리를 사용하는것이 아니라 이 단어의 함유량을 곱해준다. 이 값이 바로 단어간의 거리가 되고 모든 단어간의 거리를 더한 값이 바로 이 문서간의 거리라고 할 수 있다.

즉, 논문에 나온 예제를 그래도 갖고 왔는데 d0와 d1간의 거리가 1.07이라고 나왔고 obama와 president간의 거리가 0.45다. 이 0.45가 바로 0.25곱하기 유클리드 거리라고 보면 된다. d0와 d1의 거리가 d0와 d2간의 거리보다 가까우므로 d0와 d1이 유사도가 더 높다고 할 수 있다.
What if word counts are different?
그럼 여기서 질문 할 수 있는게 만약에 문장이 있는데 문장안에 있는 단어의 개수가 다를 경우에는 어떻게 할까? 이는 상당히 중요한 질문이기도 하다. 이는 d0와 d3의 예제를 살펴보자. d0는 4개의 단어가 있고 d3는 3개의 단어가 있다. 그리고 아까 nomalized bag of words에서 우리가 계산했듯이 d0는 0.25씩 갖고 있고 d3는 0.33씩 함유량을 갖고 있다. 자 그러면 d3에 있는 Obama와 가장 가까운 단어는 president인데 0.25만큼 갈 수 있다. 하지만 obama에 실제 함유량은 0.33이다. 즉 0.08이 남았다. 이 남은 값을 다른 값으로 분해주는 것이다.

이렇게 함으로써 Obama같은 경우에는 president로도 가지만 great로도 간다. speak는 president와 press로도 간다. Illinois는 president와 Chicago로도 간다. 이렇게 해서 total 1.3이 나온다.


그렇다면 d0와 가장 유사한 문장은 d1임을 알 수 있다. 반면 가장 거리가 먼, 유사도가 낮은 것은 d2임을 알 수 있다.
WMD performance result
WMD가 얼마나 높은 성능을 보여주냐면 총 8개의 서로 다른 데이터 셋에서 거의 모든 것에서 1등을 차지한다. 이는 wmd가 다른 방법에 비해 상당히 월등함을 의미한다.

WMD drawback
- 계산속도가 느림
- Time Complexity : O (p^3log p)
- Relaxed WMD (RWMD) : O (p^2)
(p : 문장에 있는 유니크한 단어들의 개수)
RWMD같은 경우에는 속도가 훨씬 빠른데도 불구하고 성능이 오리지날 WMD와도 상당히 비슷한 것을 확인할 수 있다.
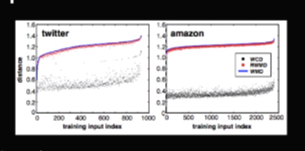
WMD와 RWMD 비교
텐서(tensor)란 무엇인가?
딥러닝에 있어 tensor에 대한 이해는 상당히 중요하다. 텐서의 종류에 대해서 먼저 알아보자.
What is tensor in deep learning?
rank 0부터 n까지 있다. rank 0 tensor는 바로 scalar value이다. 즉, 넘버 하나만 갖는다. 이 넘버를 여러 개 갖고 있으면 vector가 된다. vector는 바로 rank 1 tensor이다. 그리고 이 vector(rank 1 tensor)를 여러개 갖고 있는 tensor는 matrix(rank 2 tensor)이다. 계속해서 matrix를 아이템으로 갖는 tensor는 바로 3 tensor라고 한다. 이 3tensor를 아이템으로 가지면 4tensor라고 한다. ... (N-1)tensor를 가지면 Ntensor라고 한다.

tensor 자연어처리로 예를 들어 더 설명해보겠다. 다음 세 문장 예제가 있다. 여기 있는 워드들을 인덱스로 적으면 아래 표와 같이 나온다. 자연어 처리에서는 one hot encoding을 기본적으로 사용하는데 인덱스가 0인 hi는 총 4개의 단어니가 총 4개의 인덱스가 있고 인덱스0만 1로 표현을 해준다. john같은 경에는 인덱스1을 1로 표현해준다. James는 인덱스2번, Brain은 인덱스 3번을 1로 표현해준다. 이렇게 해줌으로써 모든 워드들이 같은 길이에 있는 벡터로 표현이 됐지만 각각 다른 부분이 1로 표현이 됨으로써 각 워드들이 다르게 벡터로 표현이 된 것을 볼 수 있다.

이제 이 워드들을 벡터로 표현할 수 있으니까 문장도 당연히 벡터로 표현할 수 있다. 다음 표를 참고하자.

이렇게 벡터로 표현된 문장들이 딥러닝 모델의 input으로 들어가게 된다. 하지만 딥러닝 모델에 input을 넣어줄 때 각 문장 하나씩 넣어주는 것보다 보통 미니배치로 넣어준다. 미니배치는 한문장이 아닌 뭉치로 넣는 것이다. 문장이 3개만 존재하므로 세 문장을 그대로 넣어보자. (즉 세개의 벡터를 아이템으로 갖는 배열을 넣는다고 보면 된다.) 배열로 들어가면 아래 그림과 같이 하나의 배열에 모든 문장이 다 들어가 있는 형식이다.

각 워드는 네개의 숫자로 표현이 되었다. 그러므로 4로 쓸 수 있다. 각 문장은 두 개의 단어로 만들어져 있다. 따라서 2라고 할 수 있다. 그리고 총 3개의 문장이 있다. 따라서 (3, 2, 4)의 shape을 갖는 tensor를 갖고 있고 이 tensor는 3개의 숫자를 갖고 있으니까 3d tensor라고 할 수 있다.
요약하면 맨 앞에 있는 숫자는 몇 개의 샘플을 갖고 있느냐이고 두번째 숫자는 그 문장에 있는 단어의 개수가 몇 개냐이고 마지막 숫자는 그 워드들이 몇개의 숫자로 표현이 되느냐를 의미한다.
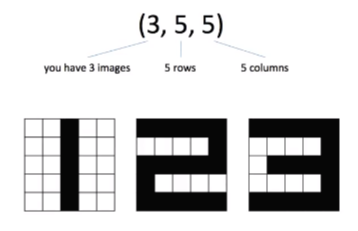
tensor example in grayscale image
이미지 프로세싱에서의 tensor를 보자. 여기 grayscale로 표현된 이미지가 있다. 총 3개의 이미지가 있으니까 3이 맨 앞의 숫자로 오고 총 5개의 행이 있으니가 두번째 숫자는 5, 또 5개의 열이 있으니가 마지막 숫자도 5가 된다. 따라서 (3, 5, 5)의 shape를 갖는 tensor이고 숫자가 3개니까 3d tensor이다.
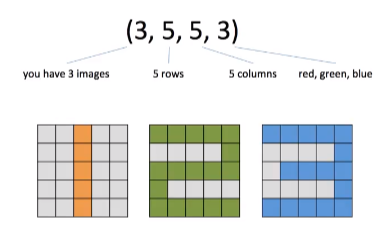
tensor example in rgb color image
그렇다면 rgb color는 어떨까? (3, 5, 5)는 같지만 grayscale이 아니므로 빨간색, 녹색, 파란색의 관련된 각각의 숫자 표현이 들어가게 된다. 따라서 이는 4d tensor이다.
tensor example in rgb color vedio
마지막으로 비디오의 경우도 간단하다. 예제처럼 3개의 비디오가 있다. 총 3개의 비디오가 있는데 각 이미지는 5개의 프레임 이미지로 구현이 되어 있다. 각 이미지는 우리가 봤던 예제처럼 5개의 행과 5개의 열로 되어 있다고 가정해보자. 그리고 rgb color를 쓴다면 (3, 5, 5, 5, 3)의 shape를 갖는 tensor이고 5d tensor이다.

순환 신경망 (RNN)
다음과 같은 문장이 있다고 해보자.
- I google at work (나는 일할 때 구글을 쓴다) : 여기서 google은 동사이고 work는 명사이다.

비슷한 문장으로
- I work at google (나는 구글에서 일한다) : 여기서 work는 동사이고 google은 명사이다. work는 I 다음에 왔으므로 동사이고 google은 전치사 뒤에 왔으니까 명사라고 추론할 수 있다.

이러한 추론 과정을 모데링 한 것이 바로 RNN이다.
Sequence is important for POS training
이 모델을 가지고 예제를 한 번 돌려보자. I가 들어오면 대명사라고 예측이 됐다고 가정을 하고 work가 input으로 들어오면 과거의 I라는 값이 영향을 주게 된다. 따라서 work가 동사라고 판단할 수 있게 된다. 그 다음에 google이 input으로 들어오면 I work at 이라는 값이 들어와서 google은 명사일 확률이 높다고 판단할 수 있다.

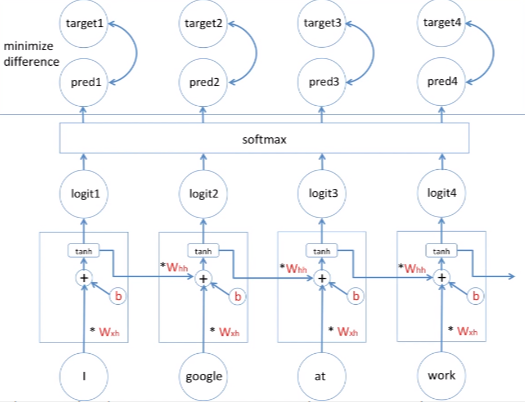
이 모델을 직접 구체적으로 살펴보자. 아랫부분은 우선 x라고 표현하자. 딥러닝에서 x는 보통 input을 뜻한다. 그리고 윗부분은 y로 output을 표현한다. 그리고 가운데 있는 hidden state를 h라고 표현했다. 중요한 점은 h1에서 나가는 것을 보자. output과 state가 동일한 값을 나가는 것을 볼 수 있다. 가장 중요한 것은 이 셀(두번째 셀?)에는 두가지 weight이 존재하는데 input이 들어올 때 w_xh와 곱해진다. 그리고 과거의 값이 들어올 때 W_hh와 곱해진다. 이 두개의 값을 고려해가지고 현재 hidden state값이 정해지게 된다. 어떻게 고려할까? 이 고려한다는 뜻은 수학적인 모델에서는 +로 표현을 해왔다. 즉 그냥 더해주는 것이다. x2가 W_xh와 곱해진 값이 과거의 state가 W_hh와 곱해진 값을 더한 값이다. 이렇게 두가지 상황을 고려한 것이다. 그리고 딥러닝 모델에는 편향 값(b)를 더해준다. 편향 값을 가짐으로써 딥러닝 모델의 학습이 보다 수월해진다. 마지막으로 tanh 활성화 함수를 넣어서 딥러닝 모델의 비선형성을 부가시킨다. 즉 마지막 아웃풋은 바로 activation function의 출력값이 된다. tanh의 출력값이 아웃풋이 되고 state의 값으로 나가게 된다.

품사 분류기 이러한 품사 분류기를 보여드렸는데 어떻게 그 품사를 분류할 수 있을까? 이 모델 위에 소프트맥스를 넣었다. 소프트맥스를 넣으면 이 소프트맥스의 아웃풋은 확률값이다. 이 모델 역시 supervised learning model이다. 즉 모든 데이터에는 학습시의 정답값을 알기 때문에 우리는 정답 값에 있는 모든 가능한 품사를 알고 있다. 4개의 품사(동사, 대명사, 명사, 전치사)가 있다고 가정해보면 소프트맥스에 지난 값은 바로 이 4개 중에 하나의 값이 가장 높은 확률을 가진다. 소프트맥스의 출력값이니까 이 4개의 값을 더하면 1이 된다(확률이므로). 즉, pronoun이 0.8로 가장 크므로 I는 대명사이다. 두번째에서는 verb가 0.7로 가장 크므로 work는 동사가 된다. google은 noun이 0.8이므로 명사라고 분류할 수 있는 것이다. 두번째 문장에서는 google이 0.6으로 동사가 되고 work가 0.7로 명사로 분류된다.


학습과정에 대해서 한 번 알아보자. 소프트맥스에 들어가는 input은 보통 logit이라고 표현한다. 소프트맥스의 output은 보통 prediction이라고 한다. 학습은 바로 이 prediction값과 supervised learn이니까 언제나 정답을 알고 있다. 그 정답을 target이라고 표현해 놓았다. 정답과 모델의 예측값을 비교함으로써 그 둘의 차이를 줄여 나가는 과정에 비교함으로써 그 둘의 차이를 줄여나가는 과정이 바로 학습과정이라고 할 수 있다. 줄여나가는 과정을 통해서 W_xh와 bias, W_hh값을 최적화(조금씩 변형)시켜준다. 어떻게 최적화하냐면 gradient descent를 써서 조금씩 변형해준다. 중요한 점은 W_xh가 네번 쓰여 있지만 단순히 하나의 변수일 뿐이고 W_hh도 마찬가지로 하나의 변수일 뿐이다. 편향값도 마찬가지다. 여러변수가 아니고 하나의 변수의 변형이다 보니까 back propagation이라고 부르지 않고 각 타임 시리즈마다 있는 동일한 변수를 바꾸는 것이기 때문에 back propagation through time(bptt)이라고 부른다.
Sentiment Analysis
문장에 있는 어떤 감정인지를 분석해보자. traffic ticket fines은 교통벌금부과라는 뜻이고 sentiment(감정)은 행복하지 않다고 할 수 있다. traffic is fine은 비슷한 문장이지만 다른 감정을 갖는다.


이러한 감정 분류기는 어떻게 만들어낼 수 있을까? pos같은 경우에는 output이 상당히 중요했지만 sentiment analysis 경우에는 마지막 state값이 상당히 중요하다. 따라서 소프트맥스는 위쪽이 아닌 옆쪽에 있다. 마지막 state값을 소프트 맥스에 넣어주고 소프트맥스의 output이 바로 우리의 예측값이 된다. sentiment analysis의 아웃풋이 happy/unhappy만 있을 경우에는 binary classfication이 된다. 그래서 prediction값으로는 happy 60%, unhappy가 40% 이렇게 나온다.

같은 방법으로 supervized learning이고 정답을 알고 있기 때문에 우리의 prediction 예측과 정답값의 차이를 죽여나가는 과정이 바로 학습과정이 된다. bptt를 통해 W_xh그리고 W_hh, bias 값을 조금씩 변형에서 이 둘의 차이를 최소화한다.
Simplify of model diagram
다이어 그램을 조금 단순화시켜보자. 앞에서도 설명했듯이 W_xh와 W_hh, bias는 여러번 등장하지만 하나의 value이다. 따라서 다음과 같이 단순화 할 수 있다. 아래 의 공식처럼 나타낼 수도 있다. 현재 state는 tanh의 아웃풋이고 tanh안에는 현재 입력값에 W_xh를 더한 것 + 과거의 state에 W_hh를 곱한 것 + 편향 값이 된다.

LSTM 쉽게 이해하기
Q. 다음 문장의 빈칸에 들어갈 단어로 알맞은 것은 무엇일까?

A. 이전 문장들을 통해 John이라는 사람에 대해 이야기 하고 있으므로 주어로는 He가 들어와야 한다. 이러한 문제는 지난 강의에서 봤듯이 RNN으로 풀 수 있다.
Q. 그렇다면 문장이 길어졌을 경우에도 간단한 RNN으로 이 문제를 해결할 수 있을까?
A. 그럴 수도 있고 아닐 수도 있다. 긴 문장일 경우에는 약간의 문제가 있을 수도 있다. 그 문제에 대해서 파악하고 솔루션으로 나온 LSTM에 대해서 한 번 알아보자.
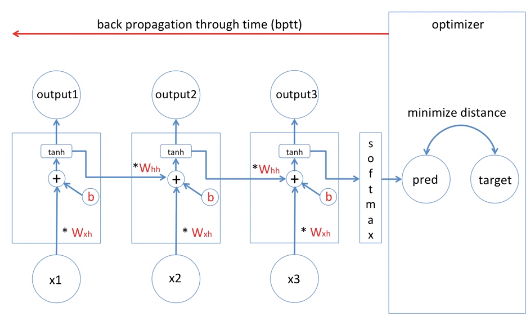
가장 먼저 할 것은 RNN의 학습에 대해서 이해해야 한다. 아래 간단한 RNN이 있다 총 세 개의 input을 갖고 그에 따라 세 개의 셀이 있고 세 개의 prediction값, output이 있다. 그에 따라서 supervised learning이니까 답이 존재한다. 답은 target이라고 하겠다. Error는 target과 prediction값의 차이다. 차이가 클 수록 에러는 높은 것이고 차이가 작을수록 에러가 적다. 왼쪽 그림을 간략화 하면 오른쪽과 같다.


input으로 x가 있고 hidden state와 error가 있다. 가중치는 w로 표시했다. 학습에 대해 이야기하기에 앞서 가장 먼저 알아야 될 것은 Gradient descent이다. 딥러닝 모델은 주로 Gradient descent를 학습하는데 사용한다. 위 예시 역시 Gradient descent를 쓴다.


가중치 업데이트 식, 미분 식 간단하게 새로운 가중치는 기존의 가중치에서 learning rate 곱하기 에러를 가중치로 미분한 값을 하면 새로운 가중치로 업데이트 된다. 미분 식을 자세히 살펴보면 미분식에서 에러를 가중치로 미분한 값은 E1, E2, E3의 미분 값을 각각 더한 것과 같다.
BPTT with long sequence

E3를 가중치로 미분한 값을 구하는 과정은 (hidden state3에 대한 미분 값) + (hidden state2에서 일어난 미분값) + (hidden state1에서 일어난 미분값) = (E3에 대한 가중치 미분값)이다. 여기서 우리가 알아야 할 것은 바로 미분값들을 여러차례 곱한다는 것이다. back propagation through time을 통해서 미분 값을 여러번 곱하게 되는데 짧은 sequence같은 경우엔 큰 문제는 없다.
Gradient Vanishing / Exploding
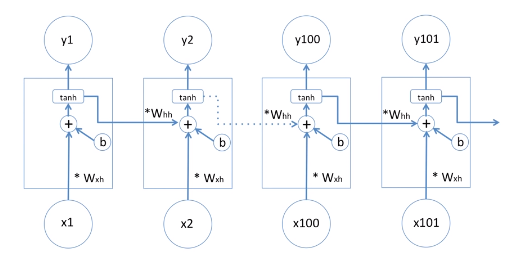
하지만 긴 sequence같은 경우에는 즉, 문장에 100개 이상의 단어가 있는 경우에, 100번 정도 곱하기를 해야한다.
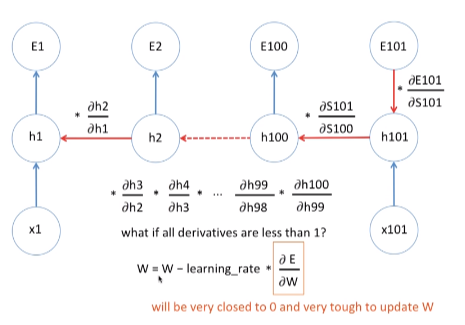

(좌) case 1 (우) case 2 case 1) 만약에 미분 값이 1보다 작다면 이를 100번 넘게 곱할 경우 0과 상당히 가까운 값이 나온다. 이 숫자가 1,000개, 10,000개가 된다면 거의 0인 숫자가 나온다. 이러한 경우 새로운 가중치 값은 기존의 가중치 값과 거의 차이가 없다. 즉, 학습을 아무리 길게 한다고 해도 가중치의 값이 거의 변하지 않는 것이다. 학습이 상당히 길어지고 비효율적이다. 이러한 현상을 Gradient Vanishing이라고 한다.
case2) 만약에 모든 미분 값들이 1보다 크다면 이를 100번 이상 곱한다고 생각해보자. 미분값을 2라고 가정하자. 100번 곱하면 값을 상당히 커진다. 새로운 가중치 값은 기존의 가중치 값과 상당히 다른 값을 갖는다. 즉 가중치 값이 왔다갔다 하게 된다. 트레이닝이 한 곳으로 가지 못하게 된다. 이러한 현상을 Gradient Exploding이라고 한다.
LSTM : Introducing memory cell in RNN
long sequence의 경우 발생하는 문제에서 (nlp에서는 단어가 많거나 문장이 상당히 많은 경우) 간단한 RNN으로는 비효율적이라는 것을 알 수 있다. 이런 문제를 극복하기 위해 나온 것이 LSTM이다.

위에 그림을 보면 오렌지색 선이 추가된 것을 볼 수 있다. 이 라인을 memeory cell이라고 부른다. 다음 예시를 살펴보자.

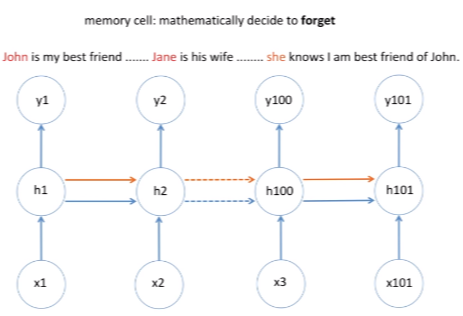
(좌) 예제1 (우) 예제 2 (예제1) John에 대한 이야기만 나온다 이러한 경우 오렌지 라인은 John에 대한 정보를 계속 간직하고 있어야 한다. 그리고 he라고 정보를 출력해 주어야 한다.
(예제2) John에 대해 이야기를 하다가 최근 들어서 Jane에 관한 이야기를 한다. Jane은 그의 와이프이다. 이때 마지막 문장에서 주어를 선택하라고 했을 때 메모리 셀 같은 경우에는 새로 들어온 Jane에 대한 정보(나중에 들어온 정보)를 기억하고 있어야 한다. 따라서 어떠한 정보를 잊는/기억하는 메커니즘이 LSTM 셀에 들어있다.
LSTM cell
LSTM cell은 딥러닝 모델이고 딥러닝 모델은 수학적인 모델이니까 어떠한 정보를 잊고 기억하고 있는 모든 것들이 전부 다 수학적인 공식이다. 그 수학적인 공식에 대해 지금부터 알아보자. 다음 그림의 LSTM cell은 가장 간단한 모양이다. 셀에 오렌지색과 파란색 라인이 들어오고 output도 있지만 오렌지색과 파란색 라인이 옆에 있는 셀로 전파가 되게 되어있다.

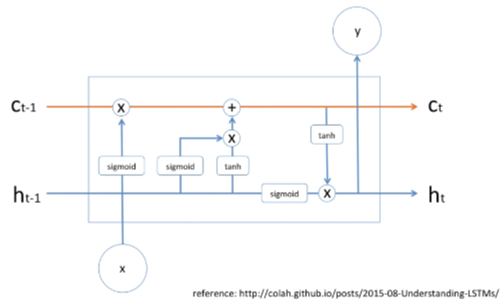
LSTM cell 기억하고 잊는 것들이 수학적으로 구현이 되어 있다고 했는데 그 부분에 대해서 간략하게 알아보자.
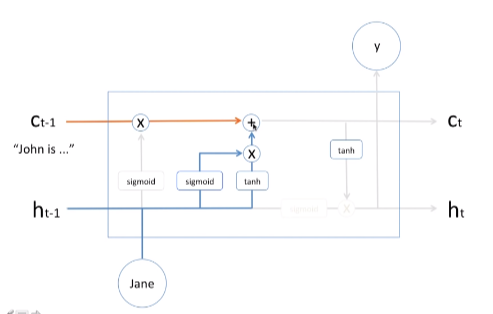
LSTM cell : forget mechanism

forget mechanism 과거의 문장들이 존은 내 친구이며 축구를 잘하고 이런 문장들이 있다고 하자. 이것들이 C_t-1에 있다. 이 정보가 오렌지색 선으로 넘어간다. 그런데 지금 새로운 단어 Jane이라는 정보가 들어왔을 때 h_t-1(과거의 hidden state)와 함께 와서 시그모이드(sigmoid)로 들어온다. 시그모이드의 출력값은 0부터 1까지이다. 즉, 확률값이라고 할 수 있다. 확률이기에 퍼센트로 이야기 할 수도 있다. X(곱하기)는 과거의 정보에 몇 퍼센트만 기억하라는 의미이다. Jane이 들어왔으니까 이 시그모이드의 결과값으로 20%가 나왔을 때 과거의 너가 알고 있는 기억(John is...)에 20%만 남겨놔라 라는 뜻이 된다. 이는 결국 까먹으라는 매카니즘을 수학적으로 구현했다고 볼 수 있는 것이다.
당연히 학습 과정을 통해서 forget machnism에 있는 weight, bias value가 학습이 되게 되어 있다. 그러므로 인해서 새로운 Jane이라는 정보가 들어왔을 때 메모리 셀에게 과거의 정보는 20%만 기억하라고 하게 된다.
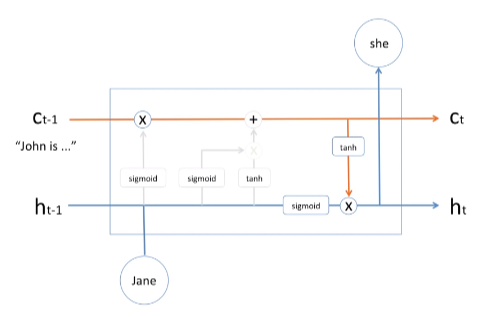
LSTM cell : input mechanism
input mechanism 과거의 정보는 어느정도 잊었고 이제 새로운 정보를 메모리 셀에 추가시켜야 한다. 이정보는 꼭 기억해야해 하는 정보가 들어가는 부분을 다음과 같이 도식화했다. hidden state 과거의 것과 현재의 input이 들어와서 sigmoid와 tanh가 서로 곱해진다. 중요한 점은 +이다. 새로운 정보를 어떻게 수학적으로 잘 조리를 해가지고 과거의 메모리 셀의 정보를 더했다. 즉, 새로운 정보가 메모리 셀에 더해지는 과정이다. 수학적으로 새로운 정보를 더하고 있다. 물론 sigmoid와 tanh앞에 weight, bias value가 있다. 이것 역시 학습과정을 통해서 최적화 되게 되어있다.
LSTM cell : output mechanism
output mechanism 메모리 셀에 있는 정보가 tanh를 통해서 들어오고 그리고 hidden state와 현재의 정보고 sigmoid를 통해서 들어오고 해서 서로 곱한다. 이 곱해진 값이 output으로 출력이 되고 또한 이 값이 다음 hidden state로 넘어가는 것을 확인할 수가 있다.
시퀀스 투 시퀀스 & 어텐션 모델 (인공신경망 기계번역)
Word to Word traslation?
'I love you'라는 영어 문장을 어떻게 기계번역할 수 있을까? 가장 탄탄한 방법은 각각의 단어를 번역하는 것이다.

각각의 단어를 번역하는 방법에는 몇가지 문제점이 존재한다.
i) 하지만 영어와 한국어의 어순이 다르기 때문에 각각의 단어를 번역하는 것은 조금 어색하다. (영어는 SVO language, 한국어는 SOV language이다.)

문제점 1 ii) 'How are you?'라는 3개의 단어를 한국어로 번역하면 '잘 지내?'로 2개의 단어가 된다. 그러므로 단어별로 번역하는 것은 어색한 문장이 될 확률이 높다.

문제점 2 따라서 단어별로 번역하는 것은 좋은 방법이라고 할 수 없다.
Let's use RNN
자 그렇다면 RNN을 활용해보자. I가 먼저 들어오고 다음으로 love가 들어오고 you도 들어온다. 결과적으로 최종 RNN 셀에 state는 I love you라는 인포메이션을 함축하고 있다. 이 벡터를 바로 context vector, 문맥 벡터라고 한다.
이 문맥 벡터로 부터 이제 번역을 시작한다. 시작하는 것이므로 start라는 사인을 준다. Nan이 나오고 다음으로 nul이 나왔고 saranghey나오면 end라는 시그널이 나올때 까지 쭉 번역을 이어준다. 이런 식으로 번역을 한다면 단어가 3개 들어와도 2개의 단어로 번역이 끝날 수도 있다. 그리고 단어의 순서가 다르더라도 이 기계학습을 트레이닝함으로써 svo language를 sov language로 만드는 것도 가능하다.

encoder decoder architecture 이 방법을 바로 Encoder Decoder Architecture라고 하고 때로는 시퀀스 투 시퀀스 모델이라고 한다. Encoder가 하는 주 역할은 각 단어를 순차적으로 받음으로써 최종적으로 context vector를 만드는 것이다. Decoder의 역할은 이 context vector로부터 기계번역을 시작한다. start부터 end까지 받아서 그 안에 있는 단어들이 순서, 바로 번역이 된다.
하지만 이 방법에도 문제점이 있다.
단어의 사이즈가 적을 경우에는 문제가 되지 않지만 단어의 사이즈가 많을 땐 문제가 생긴다. 왜냐하면 context vector는 하나의 고정된 사이즈의 벡터이다. 즉 문장이 길어질 경우 혹은 context vector 사이즈가 충분이 크지 않다면 모든 정보를 함축하기에는 이 사이즈가 작다는 문제가 있다.
예제처럼 상당히 긴 99개의 단어가 있다고 하자.
Q. 이것을 고정된 사이즈의 벡터에 담는다면 모든 정보를 담을 수 있을까?
A. 그렇지 않다.

이 번역을 하다보면 충분한 정보가 없기 때문에 번역이 완벽하지 않다, 충분치 않은 번역이 이루어진다고 얘기한다.
이러한 문제를 어떻게 극복할 수 있을까? 리서치페이퍼에서는 Attention Mechanism을 이용하는 것을 추천하고 있고 이는 좋은 결과를 보여준다.

이전에 설명했던 Encoder Decoder Architecture에서는 Encoder에 나왔던 모든 스테이트들을 활용하지 않았다. 단순히 마지막에 나온 state를 context vector라 불렀고 하나의 context voctor에서 번역이 이루어졌다. 리서치페이퍼에서 주장하는 것은 encoder에서 나온 각각의 state, 각각의 모든 RNN cell의 state를 활용하자는 것이다. 이 state들을 활용해서 decoder에서 다이나믹하게 context vector를 만들어서 번역하면 고정된 사이즈로 발생하는 문제를 해결할 수 있다.
이로써 얻는 장점은 2가지가 있다.
1) 고정된 사이즈의 context vector가 아니다. 하나의 고정된 사이즈의 context vector에서 오던 문제를 다양하게 각각의 state별로 context vector를 새롭게 만드는 것이다.
2) Encoder에 있었던 모든 state중에서 우리가 집중해야 될 단어들에게만 집중할 수 있는 매카니즘을 따로 설계할 수 있다는 것이다.
Let's practice with simple example "I love you" / Attention machanism
다음 예시를 통해서 좀 더 구체적으로 살펴보자. 시퀀스 투 시퀀스 위드 어텐션 메카니즘을 보자.

인코더 파트는 동일하다 I, love, you를 각각 받아 최종적으로 h3가 나온다. 이 h3는 전통적인 시퀀스 투 시퀀스 모델에서는 context vector였다. 그러나 이번에 보여줄 방법은 다르다.
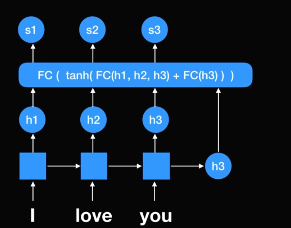
여기 FC(flip connect)? network가 있다. h1, h2, h3(인코더 파트에서 나왔던 모든 RNN셀의 스테이트들)를 활용한다. 그리고 최종으로 나왔던 h3를 넣었다. 왜냐하면 현재 상황에서 디코더에서 나온 값이 하나도 없기 때문에 단순히 전에 있던 스테이트 값을 넣었다. Flip connect network를 통해 나온 output값은 s1, s2, s3다. 즉, 각 인코더에 있던 RNN셀에 있떤 스코어들이다.
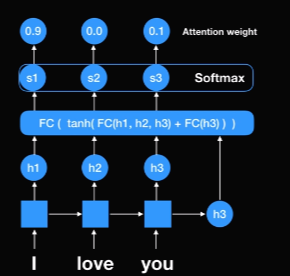
그리고 여기에 softmax값을 취해주면 확률 값이 나온다. I는 90%, love는 0%, you는 10%가 나왔다. 이것을 Attention weight라 부르고 이 값들은 얼마만큼 우리가 focus할 것인지를 나타낸다. (I는 90% focus, you는 10% focus, love는 focus하지 않음)

그래서 첫번재 문맥 패턴을 만든다. cv1은 context vector1을 뜻한다. cv1 = h1*0.9 + h2*0 + h3*0.1이 된다. 즉, 이 첫번째 문맥벡터는 I는 90%를, you는 10%를 focus한 값이다. 이 context vector를 이제 디코더 파트에는 첫번째 RNN 셀에 넣어주게 되며 이제까지 번역한 것이 없기 때문에 <start>라는 시그널을 넣어준다.
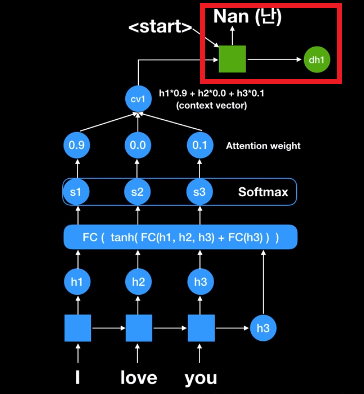

첫번째 단어, 두번째 단어 이제 'Nan(난)'이라는 output이 나오게 된다. 두번째 단어는 어떤 것으로 나올까? 두번째 단어는 디코더에 있는 현재 스테이트 값이 FC network에 들어가게 되어 있다. 중요한 것은 h1, h2, h3가 항상 쓰인다는 것이다. 즉, 인코더에 있는 RNN셀의 스테이트 값들이 항상 쓰이는데 왜냐하면 이 값들 중에서 어떤 값에 우리가 주요하게 focus할 것인가를 우리가 계산해야되기 때문이다. softmax를 지나서 하드코드를 했지만 attention weight를 보면 you가 90%다. 이말은 나는 you에 90% focus하고 싶고 I에 10% focus하고 싶고 love에 focus안하겠다는 의미이다. 이렇게 해서 최종적으로 cv2= h1*0.1 + h2*0 + h3*0.9 값이 된다.
이는 아까의 context vector와 다른 context vector이다. 단순히 한 개의 context vector만 사용한 과거의 시퀀스 투 시쿠너스 모델보다 다이나믹하게 context vector를 만드는 '시퀀스 투 시퀀스 + 어텐션 메카니즘'이 좀 더 방대한 양의 인포메이션을 함축하는데 있어 더 효율적이다라는 것을 리서치 페이퍼에서 얘기하는 것이다.


세번째 단어, end 시그널 따라서 이 context vector가 두번째 RNN cell(디코더)에 들어가게 된다. 이전 cell에서 나왔던 output값이 input으로 들어오게 된다. 해서 'Nan(난)'이 들어오고 이 cv2가 들어와서 결과적으로 'nul(널)'이 나온 것을 볼 수 있다.
같은 방식으로 이번엔 dh2가 FC network에 들어갔고 다시 한 번 h1, h2, h3가 들어갔다(이들은 항상 필수로 들어감, 왜냐하면 세가지 중에서 어떤 값에 더 집중할 것인가에 관심있기 때문). Attention weight로 이번에 love에 95% focus하고 싶고 I와 you에는 별로 관십이 없는 것을 볼 수 있다. 해서 context vector가 만들어지고 결과적으로 'saranghey(사랑해)'라는 값이 나왔다. 그리고 <end> 시그널이 나올 때 까지 한 다음에 결과적으로 start와 end안에 있는 값인 'Nan nul saranghey(난 널 사랑해)'가 정답으로 나온 것을 볼 수 있다.
이 과정들에서 중요한 것은 Attention weight이다.
i) Attention weight를 통해서 항상 인코더에 나온 스테이트를 어디를 focus해서 볼 것인지 알 수 있다.
ii) 두번째는 context vector가 각각 스테이트 별로 디코딩할 때마다 달라진다는 것을 볼 수 있다.
seq2seq with attention vs. traditional seq2seq
논문을 보면 다음과 같은 결과가 나온다. RNNsearch같은 경우에는 seq2seq model with attention machanism이고 RNNencodder는 traditional seq2seq(attention 없는 모델)이다. 50과 30이라는 숫자는 각각 최대 50, 30개의 단어를 통해서 학습한 것을 의미한다.

결과는 상당히 놀랍다.
seq2seq + attention machanism : 단어가 적고 많음에 상관 없이 놀라운 퍼포먼스를 보인다.
Teacher Forcing
Q. 만약에 prediction값이 틀렸을 경우에는 어떻게 할까?

Teacher Forcing 예를 들어 'Nan(난)'이 아닌 'Na(나)'가 나온 것이다. 이미 틀린 값은 FC network에 넣으면 문제가 발생한다.
이러한 문제를 극복하기 위해서 플렉션 값을 넣는 것보다 input으로 정답을 넣는다. 과거에는 잘못됐음에도 불구하고 두번째는 정답을 입력값으로 넣어줌으로써 이 학습을 조금 더 빠르고 효율적으로 만들어준 것이 Teacher forcing이다.

레퍼런스 링크
트랜스포머(Attention is all you need)
Transformer는 기존 인코더, 디코더를 발전시킨 딥러닝 모델이다. 가장 큰 차이점은 RNN을 사용하지 않는다는 점이다. Transformer는 기계번역에 있어서 기존 RNN기반 인코더와 디코더보다 학습이 빠르고 성능이 좋아서 큰 관심을 이끌고 있다.
How faster?
Transformer는 어떻게 학습이 더 빠르게 될 수 있었을까? 가장 큰 이유는 RNN을 사용하지 않기 때문이다. Transformer를 한단어로 정리하면 '병렬바'이다. 즉, 최대한 한방에 처리하려는 특징을 갖는다(Paralleization).
RNN vs.Transformer
RNN : 순차적으로 첫 입력 단어부터 마지막 단어까지 계산해서 인코딩함
Transformer : 한 방에 이 과정을 처리
RNN based encoder decoder
다음은 전통적인 RNN기반 encoder, decoder는 입력값이 'I love you'일 경우이다.

RNN based encoder decoder 'I'부터 순차적으로 상태값을 계산하고 나온 최종 상태 값을 context vector로 사용하게 된다. decoder는 이 context vector를 기반으로 end 시그널이 나타날 때까지 입력된 문장을 번역하는 역할을 한다. 위 예시는 가장 전통적인 인코더 디코더 모델이다. 이는 context vector가 고정된 크기라서 책과 같이 입력값이 긴 문장 같은 경우에는 고정된 context vector에 모든 정보를 저장하기 힘들기 때문에 번역 결과가 옳지 않게 나올 확률이 높다.
RNN based encoder decoder with attention
이러한 이유로 Attention machanism을 이용한 조금 더 진보된 인코더 디코더가 출현하게 되었다. 아래 그림은 Trasfomer 이전의 인코더 디코더이며 입력값이 'I study at school'인 경우이다.



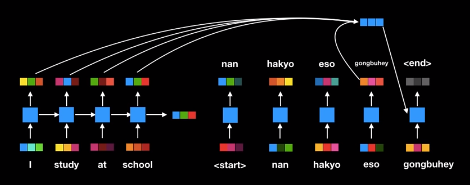
RNN based encoder decoder with attention 과정 각 단어들이 입력되고 스테이트도 계산하는 과정을 거친다. Attention 활용 인코더 디코더의 가장 큰 진보된 점은 고정된 크기의 context vector를 사용하지 않는다는 점이다. 대신 단어를 하나씩 번역할 때마다 동적으로 인코더 출력 값에 attention machanism을 수행해서 효율적으로 번역한다는 큰 장점을 갖는다. 이 모델은 고정된 context vector를 사용하지 않고 인코더의 모든 상태 값을 활용한다는 특징이 있다. 동적으로 인코더를 활용하기 때문에 긴 문장의 번역 성능이 이전 인코더 디코더 모델보다 더 나아졌다. Attention machanism은 기존 인코더 디코더의 성능을 상당히 강화시켰다고 큰 주목을 받았다. 하지만 여전히 RNN cell을 순차적으로 계산해서 느리다라는 단점이 있다.
따라서 사람들은 RNN을 대신할 빠르고 성능 좋은 방법을 찾아서 고민했고 attention만으로도 입력 데이터에서 중요한 정보들을 찾아내서 단어들을 인코딩할 수 있지 않을까 생각하게 되었다. 그 결과가 바로 Attention is all we need이다.
Attention is all we need

RNN의 순차적인 계산은 Transformer에서 단순히 행렬 곱으로 한 번에 처리가 가능하다.

Transformer는 한 번의 연산으로 모든 중요 정보는 각 단어에 인코딩하게 된다.

여기서 Transformer 디코더의 연산 과정이 기존 attention기반 인코더 디코더와 닮아 있는 것을 확인할 수 있다.
Transformer의 큰 특징은 RNN을 성공적으로 인코더 디코더에서 제거했다는 점이다. 디코더의 번역과정은 기존 인코더 디코더 방법과 동일하게 start 사인부터 시작해서 end 사인까지 번역하게 된다. 이 대목에서 Transformer는 확실히 기존 인코더 디코더 컨셉을 간직하고 있다는 것을 확인해보자.
요약하면, 기존 인코더 디코더의 주요 컨셉을 간직하되 RNN을 없애서 학습시간을 단축하고 Attention 뿐만 아니라 더 많은 스마트한 기술들이 함께 제공해서 성능을 올리게 됐다. (Attention 및 그 외 사용된 기술은 앞으로 차차 알아보자.)
자연어 처리에서 문장을 처리할 때 실제 단어의 위치 및 순서는 상당히 중요하다. RNN이 단어의 위치와 순서 정도를 잘 활용하기 때문에 자연어 처리의 상당히 많이 활용된 이유이기도 하다. 그렇다면, RNN이 없는 Transformer는 어떻게 단어의 위치 및 순서 정보를 활용하는 걸까?
Positional encoding
포지셔널 인코딩이란 인코더 및 디코더 입력값마다 상대적인 위치 정보를 더해주는 기술이다. 바로 직전 예시에서 벡터를 작은 연속된 상자로 나타냈는데, 간단한 bit를 사용한 포지셔널 인코딩 예제를 보자.

Positional encoding 그림의 첫번째 단어 'I'에는 001, 두번째 단어 'study'에는 010, 세번째 단어 'at'에는 011, 네번째 단어 'school'에는 100을 더해주었다. 동일한 방식으로 디코더의 입력값에도 포지셔널 인코딩을 적용할 수 있다. Transformer는 이러한 bit의 포지셔널 인코딩이 아닌 sine과 cos 함수를 활용한 포지셔널 인코딩을 사용한다.

sine/cos function sine과 cos함수를 사용한 포지셔널 인코딩에는 크게 두가지 장점이 있다.
i) 포지셔널 인코딩 값의 범위는 항상 -1 ~ 1이다.
ii) 모든 상대적인 포지셔널 인코딩의 장점으로 학습데이터 보다 더 긴 문장이 실제 운용중에 들어와도 포지션널 인코딩이 에러 없이 상대적인 인코딩 값을 줄 수 있다.
Self Attention
인코더에서 이루어지는 attention연산을 self attention이라고 한다. 일단은 Query, Key, Value라는 개념만 일단 알아두자.

Self Attention 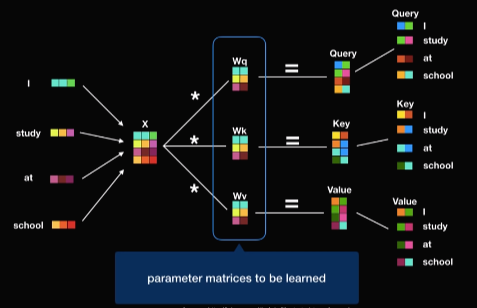
Query, Key, Value Query, Key, Value는 Wq, Wk, Wv 행렬에 의해서 각각 생성되고 이 행렬들은 단순히 wieght matrix로 딥러닝 모델 학습 과정을 통해서 최적화된다. Word embedding은 벡터이고 실제 한 문장은 행렬이라고 말할 수가 있는 것이다. 행렬을 행렬과 곱할 수 있으므로 한 문장에 있는 Query, Key, Value는 행렬 곱을 통해서 한 번에 구할 수 있다.

Self Attention 자 이제 Query, Key, Value만 있으면 Self Attention을 수행할 수 있다. 이들은 벡터의 형태임을 반드시 기억하자.

현재의 단어는 Query이고 어떤 단어와의 상관관계를 구할 때 이 Query를 그 어떠한 던어의 Key값에 곱해준다. Attention Score = Query * Key이다. 쿼리와 키가 둘 다 벡터이므로 닷프로덕트로 곱할 경우에는 그 결과는 숫자로 나온다. Attention Score가 높을수록 단어의 연관성이 높다.
Attention Score를 0부터 1까지의 확률 개념으로 바꾸기 위해 소프트 맥스를 적용해준다. 논문에서는 소프트맥스를 적용하기 전에 Score를 키 벡터의 차원의 루트값으로 나눠주었다. 논문에 따르면 벡터의 차원이 늘어날수록 닷프로덕트 계산식 값이 증대되는 문제를 보완하기위해 루트를 취한다.

소프트맥스의 결과 값은 키 값에 해당하는 단어가 현재 단어의 어느 정도 연관성이 있는지를 나타낸다. 예를 들어 단어 'I'는 자기 자신과 92%, 'study'는 5%, 'at'에 2%, 'school'에 1%의 연관성이 있다. 각 퍼센트를 각 키에 해당하는 value에 곱해주면 연관성이 높으면 뚜렷해지고 낮으면 거의 희미해지는 것을 볼 수 있다.

최종적으로 attention이 적용돼 희미해진 value들을 모두 더해준다. 즉 최종 벡터는 단순히 단어 'I'가 아닌 문장 속에서 단어 'I'가 지닌 전체적인 의미를 지닌 벡터이다. 단어 임베딩은 벡터이므로 입력 문장 전체는 행렬로 표시할 수가 있다. Key, Value, Query가 모두 행렬로 저장되어 있으니까 모든 단어에 대한 모든 attention연산은 행렬 곱을 한방에 처리할 수 있다. 만약 RNN을 사용했다면 처음 단어부터 끝까지 계산 했어야 했다. 이것이 바로 attention을 사용한 병렬처리의 가장 큰 장점이다.
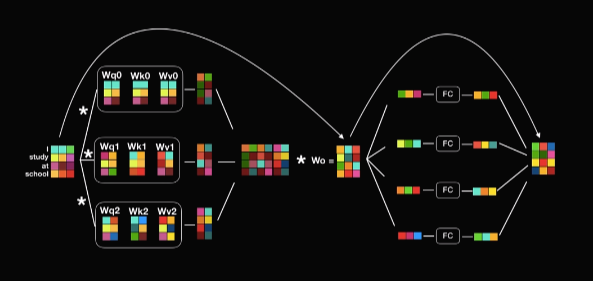
Mutil Head Attention
사실 트랜스포머는 보다 더 많이 병렬처리를 적극 활용한다. 트랜스포며는 예제에서 보았던 attention layer 8개를 병렬로 동시에 수행한다. 지금 슬라이드는 간단하게 3개의 attenton layer를 동시에 수행하는 모습을 나타냈다. 실제로는 8개이다.

여러 개의 attention layer를 병렬처리함으로써 얻는 이점은 무엇일까?
병렬처리에 대한 어텐션 레이어를 Multi Head Attention이라고 부른다. 그리고 Multi Head Attention은 예제 와 같은 기계 번역에 큰 도움을 준다.

문장은 다음과 같다. "The animal didn't cross the street because it was too tired." 여기서 it이 무엇일까? 이렇게 모호한 경우에 두 개의 다른 병렬화 된 attention이 서로 다르지만 it하고 연관성이 높은 단어에 focus하고 있는 모습을 볼 수 있다.
첫번째 attention은 animal에 포커스를 맞췄고 두번째 attention은 street에 attention포커스를 맞췄다. 사람의 문장은 대화가 상당히 많고 한 개의 어텐션으로 이 모호한 정보를 충분히 인코딩하기 어렵기 때문에 Muti Head Attention을 사용해서 되도록 연관된 정보를 다른 관점에서 수집해서 보완할 수 있다. 이것이 바로 Muti Head Attention이다.
Encoder
다음 그림이 인코더의 전반적인 구조이다. 단어를 word embeddting으로 전환한 후에 포지션널 인코딩을 적용한다. 그리고 multi head attention에 입력한다. multi head attention을 통해서 출력된 여러 개 결과 값들을 모두 이어 붙여서 또 다른 행렬과 곱해져 결국 최초 word embedding과 동일한 차원을 갖는 벡터로 출력이 되게 된다.

encoder의 전반적인 구조 각각의 벡터는 따로따로 또 flip connect는 레이어로 들어가서 입력과 동일한 사이즈의 벡터로 또 다시 출력이 된다. 여기 중요한 것은 이 출력 벡터의 차원의 크기가 입력벡터와 동일하다는데에 있다. 이점을 반드시 기억해두길 바란다.
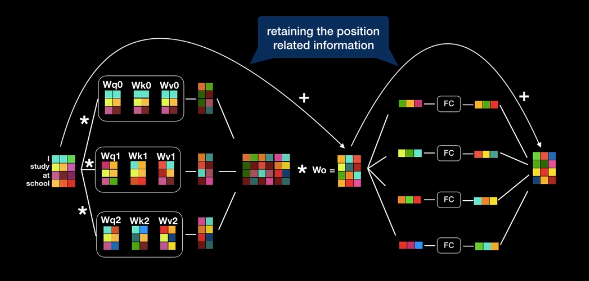
Residual Connecton followd by layer normalization word embedding에 positonal encoding을 더했던 것 기억하는가? 딥러닝 모델 학습하다 보면 역전파에 의해서 positonal encoding이 많이 손실될 수가 있다. 이를 보완하기 위해서 Residual Connection으로 입력된 값을 다시 한 번 더해 주는 것도 눈여겨 봐야한다.

encoder layer Residual Connection 뒤에는 layer normalization을 사용해서 학습 효율을 더 증진시킨다. 파란 박스가 encoder layer이다. encoder layer의 입력벡터와 출력벡터의 차원의 크기가 같다는 것을 기억하고 있을 것이다. 즉, encoder layer를 여러개 붙여서 또 사용할 수 있다는 것이다.
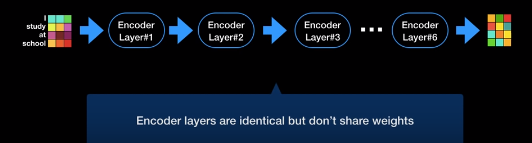
트랜스포머 인코더는 실제로 인코더 레이어 6개를 연속적으로 붙인 구조이다. 중요한 점은 각각의 인코더 레이어는 서로 모델 파라미터 즉 가중치를 공유하지 않고 따로 학습시킨다. 트랜스포머 인코더의 최종 출력 값은 6번재 인코더 레이어의 출력값이다.
여기까지가 encoder에 대한 정리이다.
Decoder
디코더에 대해서도 알아보자. 디코더는 인코더와 상당히 유사하다. 동일한 6개의 레이어로 구성된 것도 확인 가능하다. 디코더는 기존 인코더 디코더의 작동 방식과 같이 최초 단어부터 끝단어까지 순차적으로 이 단어를 출력한다. 디코더 역시 어텐션 병렬처리를 적극 활용한다. 디코더에서 현재까지 출력된 값들의 어텐션을 적용하고 또한 인코더 최종 출력값에도 어텐션이 적용된다.

디코더를 통해 어떻게 영어를 한그롤 번역하는지 그림을 통해 보자. 아래 그림은 인코더의 구조이다. 디코더의 구조와 비교해보자.

encoder layer 구조 인코더에는 multi head attention, feed forward layer, residual connecton이 있다.
디코더 레이어도 인코더와 상당히 유사한 구조를 지니지만 몇 가지 차이점이 있다.

i) 첫번째 multi head attention layer는 masked multi head attention layer로 그린다. masked는 지금까지 출력된 값들을 attenetion을 적용하기 위해 붙혀진 이름이다. 디코딩 시에 아직 출력되지 않은 미래의 단어에 적용하면 안되기 때문이다.

ii) 다음 단계는 멀티 헤드 어텐션 레이어이다. 인코더처럼 key, value, quary로 연산하는데 인코더의 멀티 헤드 어텐션 레이어와 가장 큰 차이점을 디코더의 멀티 헤드 어텐션은 현재 디코더의 입력 값을 그 query로 사용하고 인코더에 최종 출력 값을 key와 value로 사용한다는데에 있다.
쉽게 설명하면 디코더의 현재 상태를 quary로 인코더에 질문하는 것이고 인코더 출력 품에서 중요한 정보를 key와 value로 획득해서 디코더의 다음 단어에 가장 적합한 단어를 출력하는 과정이라고 볼 수 있다.
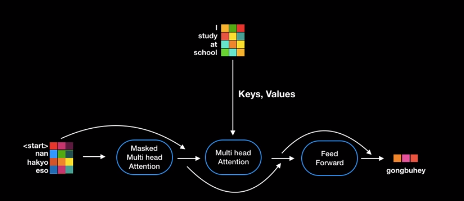
iii) 그리고 다음엔 인코더와 카찬가지로 feed foward layer를 정해서 최종값을 벡터로 출력하게 한다.
How Transformer translate the final output vector?
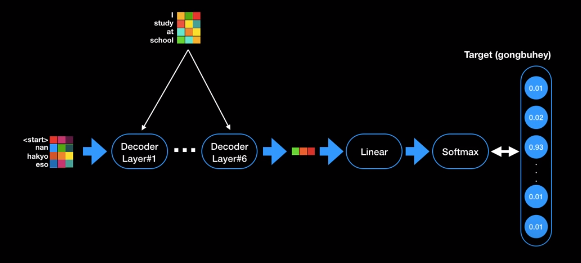
지금까지 벡터로만 출력값을 얘기했는데 그렇다면 이 벡터를 어떻게 실제 단어로 출력할 수 있을까? 실제 단어로 출력하기 위해서 디코더 최종 단에는 linear layer와 softmax layer가 존재한다.

linear layer linear layer는 소트트맥스의 입력값으로 들어갈 로직을 생성한다. softmax layer는 모델이 알고 있는 모든 단어들에 대한 확률 값을 출력하게 되고 가장 높은 확률값을 지닌 값이 바로 다음 단어가 되는 것이다.
Label Smoothing

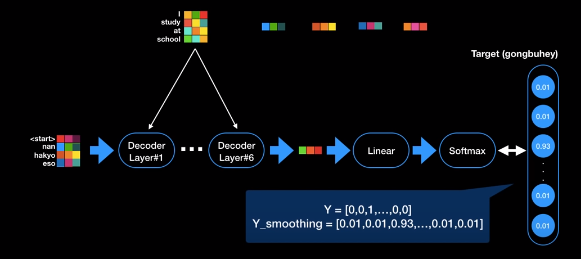
Label Smoothing 재미있게도 트랜스포머는 최종단계에도 Label Smoothing이라는 기술을 사용해서 모델의 폭퍼포먼스를 다시 한 번 한 단계 업그레이드 시킨다. 보통 딥러닝 모델의 소프트멕스로 학습할 경우에는 레이블을 원 핫 인코딩으로 전환해주는데, 트랜스포머는 원핫 인코딩이 아닌 0에는 가깝지만 0이 아니고 1에는 가깝지만 1은 아닌 값이 표현되는 것을 확인할 수 있다. 이 기술을 label smoothing이라고 한다. 0또는 1이 아닌 정답은 1에 가까운 값 오답은 0에 가까운 값으로 살짝 살짝 변화를 주는 기술이다.
모델 학습 시에 모델이 너무 학습 데이터에 치중하여 학습하지 못하도록 보완하는 기술이다. 이것이 어떻게 학습에 도움이 되는 걸까? 학습 값이 매우 깔끔하고 예측값이 확실한 경우엔 도움이 안 될 수도 있다. 하지만 레이블이 noisy한 경우 즉, 같은 입력 값인데 다른 출력 값들이 학습 데이터에 많을 경우 label smoothing은 큰 도움이 된다.
왜냐하면 결국 학습이라는 것은 소프트맥스의 출력 값과 벡터로 전환된 레이블의 차이를 줄이는 것인데 같은 데이터의 서로 상이한 정답들이 원 핫 인코딩으로 존재한다면 모델 파라미터가 크게 커졌다가 작아졌다 반복하고 학습이 원활하지 않게 된다.
실제 예제를 들어 보자. 영어로 thank you에 대한 학습 데이터가 있다고 해보자. 두 개의 thank you가 있는데 첫번째 레이블은 한국말로 고마워이고 두번째 레이블은 감사합니다라고 되어있다. 이 학습 데이터 모두 잘못된 게 아니다 하지만 원 핫 인코딩을 이 두 레이블에 적용시 고마워와 감사합니다는 완전히 다른 상이한 두 베터가 되고 thank you에 대한 학습은 레이블이 상이한 이유로 원활이 진행되지 않을 수도 있다. 이럴 경우 label smoothing을 적용할 경우 고마워와 감사합니다는 원 핫 인코딩 보다 조금은 가까워진 벡터가 되고 또한 sofrmax 출력값과 레이블의 차이 역시 조금을 줄어 들어서 효율적인 학습을 기대할 수 있게 되는 것이다.
트랜스포머에 대한 이야기는 여기까지이다.
'DSCstudyNLP' 카테고리의 다른 글
[6주차] Youtube 허민석 : 딥러닝 자연어처리 (1차) (0) 2020.02.18 [6주차] 딥러닝 2단계 : 다중 클래스 분류/프로그래밍 프레임워크 소개 (0) 2020.02.17 [5주차] 딥러닝 2단계 : Batch Normalization (0) 2020.02.10 [5주차] 딥러닝 2단계 : 하이퍼파라미터 튜닝 (0) 2020.02.08 [4주차] 딥러닝 2단계 : 최적화 알고리즘 (0) 2020.02.05