-
[6주차] Youtube 허민석 : 딥러닝 자연어처리 (1차)DSCstudyNLP 2020. 2. 18. 02:15
https://www.youtube.com/playlist?list=PLVNY1HnUlO26qqZznHVWAqjS1fWw0zqnT
딥러닝 자연어처리 - YouTube
www.youtube.com
이 글은 Youtube 허민석님의 딥러닝 자연어처리 강의 목록 13개를 수강하고 정리한 1차본입니다. 수식, 그래프 이미지의 출처는 강의 필기 캡처본입니다.
Bags of Wods란?
Back of Works는 문장을 숫자로 표현하는 방법 중에 하나다. "How are you?"라고 물었을 때 "Awesome thank you"라고 대답할 수 있다. 가방 하나 안에 문장 안에 있는 단어들은 전부 다 하나씩 넣어보자. 그럼 asewome, thank, you가 각각 하나씩 들어간다. "Greadt thank you"라고 대답하면 great, thank, you가 각각 하나씩 들어간다. 대답이 "Not bad not good"이라면 not이 2개, bad 1개, good 1개가 들어간다.
이렇게 단어의 출현 빈도로 문장을 나타낸다면 숫자로 보일 수 있다. 표를 통해 살펴보면 awesome 1개, thank 1개, you 1개로 총 7개의 단어 중에서 3개의 단어가 1이다. 이를 [1,1,1,0,0,0,0]으로 나타낸다. 이와 같은 방식으로 "Great thank you"의 경우에는 [0,1,1,1,0,0,0]으로 "Not bad not good"의 경우에는 [0,0,0,0,2,1,1]로 나타낸다.
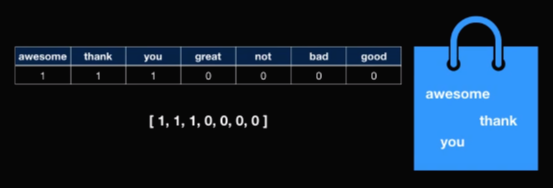
"Awesome thank you" 
"Great thank you" 
"Not bad not good" 이렇게 수치로 표현된 값을 어떻게 활용할까?
i) 문장의 유사도를 알 수 있다. (Sentence similartiy) : 유사도는 각각의 인덱스에 있는 값을 전부 다 곱해준 다음에 다 더한다.
awesome thank you와 great thank you의 유사도는 1+1=2가 된다. great thank you와 not bad not good의 유사도는 0이다. 이를 통해 첫번째 경우에서 유사도가 더 높은 것을 쉽게 구할 수 있다.

유사도 계산 ii) 머신러닝 모델의 입력값으로 사용이 가능하다. (Bag of words can be used as machine learning model's input data)
머신러닝 모델들은 전부다 수학적인 모델들이라서 f(x)함수로 표현할 수 있다. 이 x가 수치값이어야 하는데 문장은 수치값이 아니다. 따라서 이 문장을 수치로 변환해야한다. Bag of words는 바로 수치로 변형된 값 중에 하나로 이를 사용함으로써 머신러닝 모델을 쉽게 구현할 수 있다. 아래 사진은 감정분석 모델 예제이다.

머신러닝 모델의 입력값 Bag of words의 Limitation(단점)
1. Sparsity
위 예제는 7개의 단어를 들었지만 실제 사전에는 100만개가 넘는 단어가 있다. 이 경우 벡터의 차원이 100만개가 넘어가기 때문에 실제 문장 하나를 표현할 때 무수히 많은 0과 1을 비롯한 다른 수들은 상당히 적게 존재하게 된다. 이로인해 머신러닝 모델 학습을 하면 계산량이 상당이 높아지고 메모리도 사용량도 많아진다.
ex) Awesome thank you [1,1,1,0,0,0,0,0,0,0,0,0,0,0,....,0,0,0,0,0,0,0,0,0]
2. Frequent words has more power
많이 출현한 단어의 힘이 강해진다. 위에서 계산했던 방법으로 문장의 유사도를 구할 경우, the man likt the girl과 the girl love the girl의 유사도가 the the the the the의 유사도 보다 더 낮다.

3. Ignoring word orders
단어의 순서를 철저히 무시한다.
- home run(야구에서 홈런)
- run home(집으로 달려간다)
Bag of words는 단어의 출현순서를 완전히 무시하기 때문에 문장의 뜻(문맥)도 무시해버린다. home과 run이 각각 1개로 동일해 똑같은 벡터로 표현할 수 밖에 없다.
4. Out of vocabulary
보지 못한 단어의 처리를 할 수 없다. 즉 실제 머신러닝 모델을 돌리다보면 오타나 줄임말 같은 경우에는 Bag of word를 사용하면 굉장히 난감해진다. 왜냐하면 이러한 단어들은 데이터로 갖고 있기 힘들기 때문이다.
ex) good moning, tank yo, gr8, goooood
n-그램
n그램은 연속적으로 n개의 token(토큰)으로 구성된 것이다. token(토큰)은 자연어 처리에서 단어 혹은 캐릭터로 얘기하기도 한다.
1-gram (unigram)
n이 1일때 보통 유니그램이라고 한다. fine thank you라는 예제를 살펴보자.
Word level에서 유니그램은 3개의 토큰 [fine, thank, you]으로 이루어진다.
Character level로 보면 [f, i, n, e, , t, h, a, n, k, , y, o, u]로 각각의 캐릭터가 하나의 토큰으로 구분된다.
2-gram (bigram)
n이 2일 때는 바이그램으로 두 개의 단어가 하나의 묶음이 된다.
Word level에서는 유니그램은2개의 토큰 [fine thank, thank you]으로 이루어진다. 참고로 fine you는 서루 붙어있지 않기 때문에 토큰이 될 수 없다.
Character level로 보면 [fi, in, ne, e , t, th, ha, an, nk, k , y, yo, ou]로 토크나이징된다.
3-gram (trigram)
n이 3개일 때는 트라이그램이라고 한다.
Word level에서 유니그램은 하나의 토큰 [fine thank you]으로 이루어진다.
Character level로 보면 [fin, ine, ne_ , e_t, _th, tha, han, ank, k_y, _yo, you]로 세 개의 캐릭터가 하나의 토큰으로 구분된다. (가독성을 위해 띄어쓰기는 _로 표시함)
Why n-gram?
왜 n그램을 알아야할까? 자연어처리에서 n그램은 많이 사용된다.
1. Bag of words의 단점을 극복
Bag of words의 경우 단어의 순서가 철저히 무시되지만 n그램을 사용함으로써 이 문제를 극복할 수 있다. 자연어 처리에 몇가지 어플리케이션들이 있는데 박스에 뭔가 타이핑을 할 때 다음 단어에 무엇이 올지 예측이 가능하고 어떤 단어를 입력했을 때 오타를 발겨해서 더 다른 단어를 추천할 수도 있다.
bag of words의 단점
"machine learning is fun and is not boring"이라는 문장이 있다. bag of words를 사용했을 경우 다음과 같이 표현된다.

첫번째 문제는 back of words를 통해 machine learning이라는 문맥적인 것을 알고 싶지만 이는 machine이 1개 leraning이 1개라고만 얘기할 뿐이다.
두번째 문제는 바로 not이다. 위 문장은 '머신러닝은 fun하고 boring하지 않다'는 뜻이나 bag of words에 넣게 되면 not이 어디에 속한지 알 수 없다. 즉, not boring인지 not fun인지 전혀 구분할 수 없다는 것이다. 단어의 순서가 철저하게 무시됐기 때문이다. 이는 또한 위 예시문과 "machine learning is boring is not fun"문장과 bag of words에서 같은 결과가 나오게 된다는 의미이기도 하다.
2. bag of bigram의 사용
bigram(바이그램)을 사용하면 어떨까?
i) mashine learning이라는 단어가 1개, not boring이라는 단어가 캐치된게 보인다. machine learing이 하나의 term(텀)이 되고 not boring이 하나의 token(토큰)이 되어서 not이 fun이 아닌 boring과 함께 있음을 알 수 있다. 따라서 단순히 bag of words를 사용하는 것보다 bag of bigram을 사용함으로써 문맥적인 것을 숫자에 표현시킬 수 있게 된다.
ii) 두번째는 다음 단어를 예측하는 것이다. 예시로 naive한 방법을 보자. "how are you doing", "how are you", "how are they"라는 세 문장이 있다. trigram을 사용할 경우에는 2개의 how are you가 있고 1개의 are you doing이 있고 1개의 how are they가 있다. input 박스에 유저가 "how are"라고 쳤을 때 다음 단어로 예측해줘야 한다면 어떤 것을 예측할 수 있을까? 데이터 중에 "how are"다음에 you가 온 게 2개, they가 온 게 1개가 있었다. 아주 간단하게 생각하면 you라고 추천해줄 수 있다. (물론 세상에 나와있는 Next word prediction은 이보다 훨씬 진보적인 방법을 사용한다)

bigram의 next word prediction (다음 단어 예측) iii) 간단한 방법으로 spell checker를 만들어보자. quality, quater, quit 이 세가지 단어를 가지고 있다. Character level of bigram을 사용하면 다음 표와 같이 나타낼 수 있다.

character level of bigram 그리고 input box가 주어졌을 때 어떤 사람이 "qwal"이라고 쳤다고 가정하자. 그럼 Knowledge base의 우리가 가지고 있는 데이터에 qw와 wa는 존재하지 않는다. 반면에 표에 의하면 qu는 3번, ua는 2번이나 발생이 됐다. 그럼 Knowledge base를 통해서 qwal이라고 쳤을 때 qual이라고 추천해 줄 수가 있다.

이런 식으로 n-gram을 사용하면 상당히 많은 식으로 저연어 처리 어플리케이션을 사용할 수 있다.
What is TF-IDF?
TF-IDF는 Term Frequency-Inverse DOcument Frequency이다. Term이란 문서가 주어졌을 때 단어를 뜻한다.
Why TF-IDF?
그렇다면 TF-IDF는 왜 사용할까?
어떤 한 문서가 주어졌을 때 문서는 단어로 구성되어 있다. 그러면 각 단어별로 이 문서에 연관성을 알고 싶을 때 수치로된 값인 TF-IDF를 사용한다. 단어의 문서 연관성이란 무엇일까? 쉽게 말해 어떤 문장은 단어로 구현이 되어있는데 각 단어별로 이 문서에 대한 정보를 얼마만큼 가지고 있는가를 수치로 나타낸 값이다.
What is Term Frequency?
TF는 어떤 문서가 주어졌을 때 이 단어가 몇 번 출현했는지 나타내는 값이다. 이를 사용하는 가설은 '문서가 있을 때 단어가 여러번 출현했다면 여러 번 출현한 만큼 이 문서와 연관성일 높을 것이다'라는 가설 안에 TF 스코어를 사용한다. 다음 예제를 살펴보자.
ex) "a new car, used car, car review" : 단어의 개수는 총 7개이다. TF score는 다음과 같다.

TF score car 단어의 경우 3/7으로 가장 높은 TF score를 갖는다. 그러므로 가장 중요한 단어라고 할 수 있다. 실제로도 문장을 봤을 때 car가 가장 중요한 문장이다.
TF score drawback
하지만 TF score는 치명적인 단점이 있다. 다음 예시를 보자.
ex) "a friend in need is a friend indeed"

TF score를 구했을 때 a와 friend가 같은 점수로 공동 1등이다. 실제로 이 문장에서 가장 중요한 단어는 friend이다. a는 중요하지 않다. 즉, TF 가설이 틀렸다는 것을 의미한다. TF 가설은 자주 출현하는 단어일수록 점수를 높게 주어야한다는 것인데 정관사 a와 같이 연관성은 없음에도 여러 문장에 자주 출현하는 단어들이 있다. TF score 하나만으로는 이 단어가 문서와 관련된 연관성을 나타내기 힘들다는 것을 의미한다.
What is IDF?
바로 위 예시에서 보았듯이 어떤 단어들은 문서와 연관성이 없음에도 불구하고 어느 문장에서나 자주 출현하는 단어들이 있다. 그러한 단어들에게 패널티를 주기위해 IDF라는 개념을 사용한다.
공식은 간단하다.
Log( Total # of Docs / # of Docs with the term init
+1) : 로그 안에서 총 문장의 개수를 이 단어가 출현한 문장의 개수로 나눠준 값이 바로 IDF이다.때로는 0으로 나누는 수학적 에러를 피하기 위해 분모에 더하기 1을 해주기도 한다.이 예제에서는 +1을 하지 않는 공식으로 IDF score를 구해보자.IDF score
위에서 사용했던 예시문을 다시 사용해보자. 각 word별로 IDF 값을 적었다.
A : "a new car, used car, car review"
B : "a friend in need is a friend indeed"

로그 안에 분자는 총 두 개의 문장이 있으므로 2의 값이 들어간다. 단어 a의 경우 두 문장 모두에 들어가 있으므로 분모의 값이 2이고 결과적으로 log(2/2)=0이다. new 단어의 경우 한 문장에서만 출현했기 때문에 log(2/1)=0.3이 된다. 이런식으로 IDF 값을 결정한다.
TF-IDF
다음 표는 TF-IDF 값을 나타낸 것이다.

첫번째 문장 A에서 가장 높은 TF-IDF score는 0.13으로 해당 단어는 "car"이다. 두번째 문장 B에서 TF score만 봤을 때에는 "a"와 "friend"가 똑같은 값이였지만 TF-IDF score에서는 "friend"가 0.08로 가장 높은 점수를 갖고 "a"는 a의 IDF값이 0이기 때문에 0의 값을 갖는다. 즉, 문장 B에서 가장 많은 정보를 함유하고 있는 단어, 문장 B와 가장 연관성이 높은 단어는 "friend"이고 그 값은 0.08인 것을 바로 확인할 수 있다.
요악하자면 TF-IDF는 어떠한 문서/문장가(이) 주어졌을 때 각 단어별로 그 문장의 연관성을 수치로 나타낸 것이다.
자연어처리의 유사도 측정 방법
자연어처리에서 유사도 측정 방법은 크게 두가지가 있다.
1. 유클리드 거리 (Euclidean Distance)
2. 코사인 유사도 (Cosine Similarity)
1. Euclidean Distance Similarity
먼저 간단한 유클리드 거리를 사용하는 방법을 보자. 다음 그래프에 공주, 왕자, 남자라는 세 단어가 있다. 남자와 왕자의 거리는 남자와 공주의 거리보다 더 짧다. 이렇게 거리가 짧으면 유사도가 더 높다라고 판단하는 것이 유클리드 거리를 사용한 유사도 측정 방법이다. 거리 계산은 피타고라스의 정리를 사용한다.

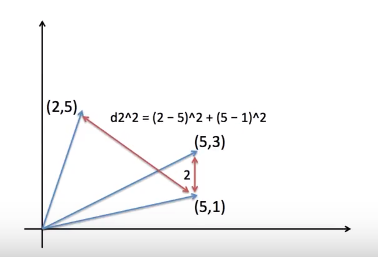
유클리드 거리 유사도의 계산방식 2. Cosine Similarity
코사인 유사도는 x축은 laundering(세탁), y축은 money(돈)이다. laundering단어 하나만 있으면 (1,0), money money laundering은 (1,2), money money money money money money는 (0,6)이다. 여기서 유클리드 거리를 사용해서 유사도를 보면 (1,0)과 (1,2) 사이의 거리(d1)가 (1,2)와 (0,6) 사이의 거리(d2)보다 짧다. 즉 (1,0)과 (1,2)의 유사도가 더 높다라는 결과가 나온다. 하지만 실제로는 money money laundering과 money money money money money money의 유사도가 더 높아보인다. 이는 벡터라는 특성 때문에 발생하는 문제이다. money가 여러번 발생됨으로써 벡터의 크기가 커지게 되는 것이다. 크기가 커지면서 거리가 점점 늘어나지만 아무리 money가 많이 나온다고 하더라도 내용 자체는 money이다.


코사인 유사도와 계산방식, 원리 따라서 magnitude, 그 벡터의 크기를 무시하고 유사도를 측정하는 것이 코사인 유사도 방식이다. 코사인 유사도 방식은 각도만 본다. 파란색과 오렌지색 선의 각도가 오렌지색과 초록색 선의 각도보다 작으므로 유사도가 더 높다. 즉, 각도가 더 좁을수록 유사도가 더 높다고 본다. 왜냐하면 코사인 그래프에서 값이 작을수록 더 높은 값이기 때문이다.
cos(θ)를 구하는 공식은 다음과 같다. 두 개의 벡터를 곱한 값을 각각의 거리로 나눠주면 된다.

코사인 공식 다음을 통해 유사도를 구하는 방식을 볼 수 있다.
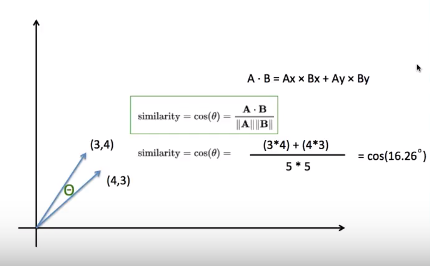
코사인 유사도를 구하는 방식 따라서 코사인 유사도 방식으로 magnitude를, 벡터의 크기를 무시한 채로 두 선 사이의 각도가 좁으면 유사도가 높다고 판단한다.
Can angle be greater than 90?
추가적으로 코사인 유사도 방식을 사용할 때 각도가 90도 보다 더 높을 수 있을까? 보통 90도를 초과하지 않는다. 왜냐하면 예제처럼 x축은 word의 개수이고 y축은 어떤 한 word의 개수로 봤을 때 word의 개수가 음수가 될 수 없다. word가 몇 번 출현한 양인데 한번도 안나오면 0이고 한 번 이상 출현하면 바로 양수가 된다. 따라서 코사인 유사도 측정시 90도가 넘어갈 수 없다. 언제나 0도부터 90도까지의 값을 갖는다.
TF-IDF 문서 유사도
How to get document similarity?
문서의 유사도는 어떻게 구할 수 있을까?
1. Bag of words를 사용해 코사인 유사도 구하기
2. TF-IDF를 사용해 Bag of words에서 word에 카운트 대신 TF-IDF를 넣어서 코사인 유사도를 활용해 문서의 유사도 구하기
먼저 코사인 유사도를 활용해 bag of words에 문서유사도를 구해보자. 다음 네 개의 문장이 있다.
d1 : the best Italian restaurane enjoy the best pasta
d2 : American restaurant enjoy the best hamburger
d3 : Korean restaurant enjoy the best bibimbap
d4 : the best the best American restaurant

다음 문장들의 bag of words는 다음과 같고 이를 벡터로 표현했다. 코사인 유사도를 계산할 수 있게 된다.


d1과 d4의 코사인 유사도는 다음과 같이 구한다. 분모의 거리는 각 벡터의 값을 제곱을 합한 값을 루트한 것이다. 분자는 두 벡터를 요소별로 곱해서 더한 값이다. 결과적으로 코사인 유사도는 0.82의 값을 갖는다. 이와 같은 방식으로 d4와 d1~d4까지의 코사인 유사도를 계산한 값을 정리하면 다음과 같다. d4와 d4는 같은 문장이므로 코사인 유사도는 최대값인 1이다.

d4를 제외하고 유사도가 가장 높은 값인 d1 문장이 가장 비슷하다는 결론이 난다. 하지만 우리가 the best the best american restaurant(d4) 라고 서치했을때 원하는 첫번째 값은 d2이다. 왜냐하면 최고의 미국 레스토랑을 찾았는데 최고의 미국 레스토랑에서 햄버거파는 결과값이 제일 먼저 나오길 바라지 the best Italian이 최고의 위치의 첫번째의 리서치 값으로 나오는 것은 서치가 잘못되었다는 것을 의미한다. 이것이 바로 단점이다.
문제는 the best 가 d1에 두 번, d4에 두 번이나 출현했다는 것, 하지만 the best는 모든 문장에 포함되어 있다. 즉, 여러분 출현한다 하더라도 그렇게 중요성이 많지 않은 단어라고 볼 수 있다. 이렇게 자주 출형하지만 중요성이 없는 단어들을 penalize하자고 한 것이 TF-IDF이다.

TF와 IDF값을 각각 구해서 곱하면 TF-IDF가 된다. (TF는 자주 출현하는 만큼 점수를 높여주지만 IDF에서 자주 출현하되 모든 문서에 많은 출현을 하면 그 값을 줄여주는 효과를 준다.) 이를 계산하고 bag of words의 단어의 개수 대신에 TF-IDF를 넣어준다. 그러면 위 표와 같은 결과가 나온다.

d1, d2, d3, d4를 각각 TF-IDF로 정리하면 다음과 같다. 이전과 같은 방법으로 코사인 유사도를 계산해주면 d4는 같은 문장이므로 최대값인 1이 나오고 그 다음으로 높은 값은 0.5로 d2가 가장 근사한 문장으로 선택된 것을 볼 수 있다.
Advantage of TF-IDF bag of words
TF-IDF bag of words의 장점은 무엇일까?
i) 구현이 쉽다. 다큐멘터리 유사도를 구하기 쉽다.
ii) 중요한 점수의 단어를 유지한다.
iii) 자주 출현하지만 여러 문서에 존재하는 중요하지 않은 단어에는 점수를 낮춰주는 역할을 수행한다.
Drawback of TF-IDF bag of words
TF-IDF bag of words의 단점은 무엇일까?
i) 오직 단어만 본다. 단어의 속에 있는 유사도를 보지 않는다.
ii) 단어를 알되 그 topic을 아는 데는 한계가 있다.
iii) 같은 의미를 가진 다른 단어들을 다루기 힘들다.
예제를 살펴보자. 다음 두 문장은 거의 비슷한 문장이지만 TF-IDF bag of words를 사용하여 유사도를 측정하면 0이 나온다. 왜냐하면 똑같은 단어가 하나도 존재하지 않기 때문이다.
- U.S President speech in public
- Donald Trump presentation to people
두번째 예제를 보자. 다음 세 문장중에서 첫번째 문장과 세번째 문장의 유사도는 몇일까? TF-IDF bag of words를 사용하면 유사도가 0이 나온다. 하지만 실제로 American restaurant menu나 hamburger pizza나 의미적으로는 비슷하다. (미국 레스토랑 메뉴에 햄버가나 피자가 속해있기 때문) 이런 의미적인 것을 캐치하지 못한다는 단점이 있다.
- American restaurant menu
- American restaurant menu hamburger pizza
- hamburger pizza
How to overcome Drawbacks of TF-IDF?
이러한 단점들을 어떻게 극복할까?
- LSA (Latent Semantic Analysis) : LSA는 간단히 말해서 바로 직전의 예제에서 두번째 문장(American restaurant menu hamburger pizza)가 존재한다. 이렇게 같이 존재하는 단어들 고려해서 svd를 취해서 서로 간의 유사도를 측정할 수 있는 방법이다.
- Word Embeddings (Word2Vec, Glove) : 각각의 단어마다 유사도가 존재한다. 이를 사용하면 TF-IDF의 단점을 극복할 수 있다.
- ConceptNet : ConceptNet은 Knowledge graph를 사용한다. 예를 들어서 버거킹과 맥도날드의 유사도를 어떻게 측정하냐면 버거킹은 햄버거를 파는 장소이고 레스토랑의 한 종류이다. 맥도날드 역시 햄버거를 파는 장소이고 레스토랑의 한 종류이다. 이렇게 무언가 여러가지 단어간의 관계를 사용해서 혹은 단어간의 그 유사도를 측정할 수 있는 것이다.
잠재 의미 분석 (LSA, Latent Semantic Analysis)
If we use bag of words, pizza and hamburger doesn't have similarity
다음과 같이 6개의 메뉴가 존재한다. 위에 3개 메뉴는 미국 음식이고 아래 3개 메뉴는 일본 음식이다.

피자와 햄버거가 동일한 미국 음식인데 만약에 bag of words를 통해 피자와 햄버거의 유사도를 구할 경우에는 몇이 나올까? 코사인 유사도를 계산하면 피자와 햄버거의 dot product(점곱)가 0이기 때문에 바로 유사도가 0이 나온다. 이는 피자와 라면의 유사도와 같다. 즉, 관계가 전혀 없다.

이는 TF-IDF를 사용해도 마찬가지다. 동일한 미국 음식임에도 불구하고 햄버거라는 문장과 피자라는 문장이 서로 동일한 단어가 없기 때문에 유사도가 0이 나온다.
Why?
같은 미국 음식이지만 유사도가 0인 이러한 현상은 왜 일어날까? 그 이유는 바로 TF-IDF와 bag of words는 단어 기반의 벡터이기 때문이다. 단어에서 topic을 구할 수 없기 때문에 유사도가 0이 나오는 것이다. 반면에 LSA는 topic 기반으로 유사도를 구할 수 있다. 이에 대해 알아보자.
Here wo have menus from restaurants
다음 메뉴들을 단어와 문장의 매트릭스로 표현해보았다. 이 매트릭스를 A라고 하자.

단어는 행으로 표시했고 문장은 열로 표시되었다. 단어가 행으로 표시되었기에 SVD(특이값 분해, Singular Value Decomposition)를 얼추 하면 3개의 메트릭스 곱으로 나타낼 수 있다. 단어가 행으로 들어갔기 때문에 U매트릭스는 토픽을 위한 단어 매트릭스라고 말할 수 있다. V^T매트릭스는 바로 문자 매트릭스이다. 가운데의 시그마 매트릭스는 토픽의 강도이다.

이 세 개의 매트릭스를 곱할 경우에는 A매트릭스와 상당히 비슷한 값이 나오는데 완벽한 상황에서는 동일한 값이 나온다. (강의에서는 소수점 이하의 첫번째 자리까지만 표시)
Document Vector
지금 우리가 관심있는 것은 단순히 문장 벡터이다. 햄버거와 피자가 유사하게 갖게 만드는 결과를 보려고 하므로 단순히 시그마 매트릭스와 V^T매트릭스를 곱한 값이 우리가 원하는 값이 된다. 이 예제의 경우 2d 필렛의 시각화를 하면 2d E~~(?)이 필요하므로 시그마 매트에서 가장 큰 1.9와 1.7만 사용한다. (왜지,,,?) 시그마 매트릭스의 특성상 이 값들은 전부 다 내림차순으로 되어 있다. 따라서 위에있는 t1과 t2만 선택하도록 한다. 그렇다면 여기 보이는 녹색 셀들만 곱하는 결과가 나온다. (2,2)와 (2,6)매트릭스를 곱하니까 (2,6) 매트릭스가 나온다.


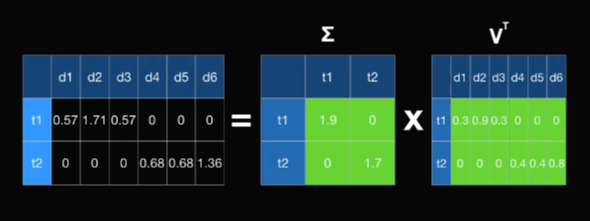
계산 과정 이렇게 결과가 나온다. 총 6개의 문장이 있었다. 6개의 문장이 t1과 t2로 표시된 것을 볼 수가 있다. 이 t1과 t2를 사용해서 2d에 시각화해보자.
Topic Similarity

2d 시각화 시각화하면 d1과 d3가 같은 위치에 있고 d2는 같은 축 상의 조금 떨어진 위치에 있다. 마찬가지로 d4와 d5가 같은 위치에 있고 d6는 같은 축 상의 조금 떨어진 위치에 있다. 여기서 코사인 유사도를 계산할 경우 d1, d2/ d1, d3/ d2, d3가 전부 동일한 1값이 나온다. 즉, 1은 최고의 값으로 동일한 유사도를 가지고 있다고 할 수 있다. 마찬가지로 d4, d5/ d4, d6/ d5, d6도 동일한 유사도 1값을 갖는다. 즉, d4, d5, d6가 같은 topic을 갖고 있다고 볼 수 있다.


하지만 녹색점과 파란색점의 코사인 유사도는 각이 90도이기 때문에 0의 값이 나온다. 즉, 녹색점과 파란색점은 유사도가 전혀 없다는 것을 의미한다.

결과적으로 t1축은 미국 음식을 나타내고 t2축은 일본 음식을 나타내는 것을 잠재적으로 알 수 있다. 이것이 바로 잠재적 의미 분석(LSA)이다. 추가적으로 d2가 d1, d3보다 멀리 떨어진 이유는 3개의 미국음식과 관련된 단어가 있기 때문이다. pizza hamburger cookie로 강도가 쎈 것이다. 하지만 코사인 유사도에서는 이 강도를 무시한다. d6와 d4, d5의 경우에서도 ramen sushi의 두 단어가 있기 때문에 한 개의 단어를 갖고 있는 d4, d5보다 조금 멀리 간 것이다.
단어 벡터 변환 (word2vec)
What is Encoding?
딥러닝 모델의 텍스트를 input으로 넣을 수 있을까? No! 할 수 없다. 하지만 숫자는 input으로 넣을 수 있다. 자연어 처리에서 보통 input은 텍스트인데 이 텍스트를 숫자로 표현하는 과정을 인코딩(encoding)이라고 한다.
예를 들어서 thank you와 love you라는 단어가 있을 때 단어는 thank, you, love 3가지가 있다. 이를 각각 0, 1, 2로 인코딩 할 수 있다.
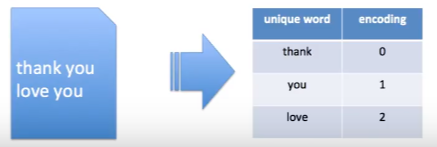
convert text to number 1 하지만 가장 사랑받는 방법은 바로 One Hot Encoding이다. 단어가 3개가 있으므로 3차원 벡터로 만들어주고 각각 (1,0,0) (0,1,0) (0,0,1)로 독립적인 벡터로 만들어준다.

One Hot Encoding One Hot Encoding doesn't have similarity
하지만 여기 문제가 있다.
i) One Hot Encoding은 유사도가 없다. 단어 간의 유사도(고맙다, 사랑한다가 고맙다, 미워한다보다 가까운 관계임)를 one hot encoding으로는 표현할 수가 없다. 이펙터 스페이스?에서 보통 유클리드 거리에 대한 거리가 가까우면 비슷하다라고 판단하는 것인데 one hot encoding을 쓰면 각각의 데이터가 거리가 같아져 버린다.

one hot encoding의 문제점 1 ii) 두 번째는 nlp에서 자주 사용하는 코사인 유사도라는 것인데 두 개의 데이터 포인트 간에 각도가 모두 90도가 나온다. 즉, 코사인 유사도가 0이 되어버려서 유사도를 발견할 수 없는 것이다.

one hot encoding의 문제점 2 이러한 문제점 때문에 Embedding이라는 것을 알아야 한다.
Embedding
인코딩 대신에 임베딩을 사용함으로써 단어끼리의 유사도를 구할 수 있다.
- 임베딩은 보통 one hot encoding보다 저차원이고 유사도를 갖는다. 아래 표를 참고하면 인코딩은 4차원이지만 임베딩은 2차원인 것을 볼 수 있다.
- 또한 비슷한 단어는 서로 가까이 분포한다.

Embedding Word2Vec
Word2Vec은 Embedding 중에 하나로 유사도 같은 경우에는 비슷한 위치에 있는 단어들 사이에서 얻게 된다. 우리는 이 비슷한 위치에 있는 단어를 이웃(neighbor)이라고 한다. 예제를 살펴보자.
Word2Vec data generation (Skipgram)
word2vec에서 skipgram이라는 방법이 있는데 이를 사용해보자.
- "king brave man"
- "queen beautiful woman"
i) window size = 1일 경우에는 왼쪽과 오른쪽으로 하나씩의 이웃만 보겠다는 것이다.

window size = 1 king의 이웃은 brave/ brave의 이웃은 king, man이 되는데 이런 식으로 표로 나타난다. word는 input이 되고 neighbor는 target이 된다. 사람이 문장만 주어지면 컴퓨터가 직접 word와 target을 만든다.
ii) window size = 2일 경우에는 좀 더 많은 데이터를 얻는다. 왼쪽과 오른쪽으로 두 개의 단어들을 보게 된다.
king은 brave, man을 이웃으로 갖는다.

window size =2 이렇게 모든 단어들이 이웃을 얻게 되었고 딥러닝에 들어가게 되는 것은 텍스트 자체가 아닌 encoding value가 input으로 들어가고 embedding을 결과로 얻게 된다.
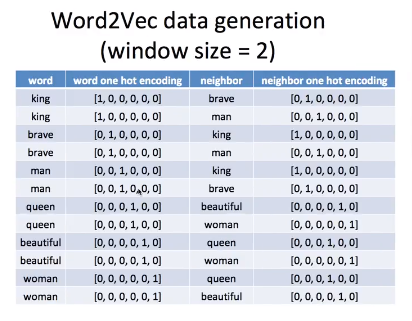
즉 맵핑 테이블은 위와 같지만 딥러닝 모델에 직접 들어가느 것은 바로 아래 표와 같은 숫자들 밖에 없는 것이다. input으로는 왼쪽의 데이터들이 들어가고 target으로는 오른쪽의 데이터들이 들어가서 중간의 hidden value의 값을 얻게 된다.

이것이 바로 Word2Vec를 얻기 위한 딥러닝 모델의 아키텍쳐이다. 총 3개의 input, hidden, output 레이어가 있다.

word2vec를 얻기 위한 딥러닝 모델의 아키텍쳐 input과 output레이어는 동일한 노드의 개수를 갖는다. 즉 one hot encoding 총 6개의 차원이 있다면 ouput도 총 6개의 차원이 있다. 단 히든 레이어는 2개의 노드만 넣었다. 왜냐하면 히든 레이어가 바로 Word2Vec이 될 것이기 때문이다. one hot encoding보다 조금 더 적은 차원의 벡터를 가짐으로써 유사도를 갖게한다.
예를 들어 king이라는 단어가 input으로 들어갔다고 가정하자. king의 이웃은 brave였다. brave같은 경우에는 target value가 0 1 0 0 0 0이고 king은 1 0 0 0 0 0이다. 그래서 input이 들어가고 hidden value에 어떤 값이 들어가게 된다. 그리고 output으로 softmax를 취하게 되면 softmax안에 있는 모든 값을 더했을 때 (sum하면 확률이므로) 1이 된다. output과 target값의 차이를 가지고 cross entropy를 계산함으로써 bag propagation을 실행하게 된다. 해서 w값이 점차적으로 변하게 된다.

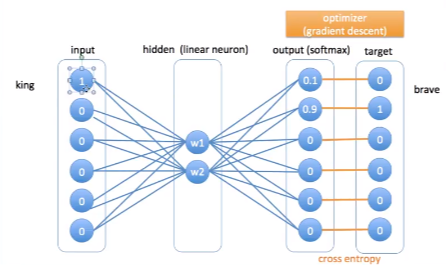




이런식으로 back propagation을 하면서 w값이 점차적으로 유사도를 갖기 위해 변형하게 된다. 반복적으로 이들을 수행하게 되면 hidden layer의 w1, w2가 결정된다. 바로 이 w1, w2값이 Word2Vec이다.

Word2Vec is hidden layer after train 예를 들면 아래 다음과 같은 매트릭스 계산이 있다. king의 [1, 0, 0, 0, 0, 0]값과 hidden layer값을 곱해본다. 그렇다면 첫번째 인덱스의 있는 값이 킹의 embedding값과 같다.(빨간색 글씨 확인) 이러한 결과가 나오는 이유는 input이 바로 one hot encoding이기 때문이다.

king이 첫번째 단어이므로 첫번째 인덱스에 있는 두 개의 노드 값이 바로 이 워드의 word2vec이다. hidden layer의 첫번재 인덱스가 king이고 두번째가 brave고 세번째가 man이고 이런식으로 lookup table로 사용할 수 있는 것이다. 이렇게 해서 lookup table에 히든 레이어 값들을 가져와보면 man과 king이 비슷한 위치에 있고 woman과 queen이 비슷한 위치에 있는 것을 확인할 수 있다.

보시는 것처럼 인코딩은 6차원이지만 임베딩은 2차원인 것을 볼 수 있다. 그리고 유사도가 다음 표와 같은 것도 확인가능하다.
tensorflow에서 구현한 것을 보자. https://github.com/minsuk-heo/python_tutorial/blob/master/data_science/nlp/word2vec_tensorflow.ipynb 에서 실행해보길 바란다. 10개의 문장 예제가 있다.

가장 먼저 stop word를 없앤다. is, a, will, be처럼 흔하게 많이 쓰이는 단어들은 제거했다. 유사도를 구하기위한 학습과정에서 도움이 안되기 때문이다. 그리고 유익한 단어들만이 남는다.

데이터를 만들기위해서 window size를 2로 설정하고 코드를 돌린다. 왼쪽과 오른쪽에 있는 이웃들을 데이터로 만들게 된다. 이렇게 데이터가 생성된 값을 볼 수 있다. king-man, strong-king.. 이 서로 이웃인 것을 확인 가능하다. 이 값들을 이제 딥러닝 모델에 넣게 된다.


딥러닝 모델의 tensorflow 디자인은 다음과 같다. 눈여겨 볼 것은 one hot encoding dimension은 word의 개수이다. word가 3개면 3차원 벡터인것처럼 word의 개수 만큼 one hot encoding벡터의 스페이스?가 결정된다.
input과 output레이어에 one hot encoding을 사용하고 word2vec임베딩은 2를 사용한다. 즉, 2차원 그래프에 바로 표시하기 위해서 word2vec은 2개의 노드만 놓는다. 그리고 hidden layer에는 activation function이 없다. 즉 linear neuron이라는 것이고 단순히 weight와 bios밖에 없다. (앞선 설명에서는 바이오스가 없었으나 바이오스를 넣어서 좀 더 학습이 효율적으로 일어나도록 했다.) output layer에는 소프트맥스를 넣었다. 소프트맥스의 cross entropy를 사용함으로써 train을 시도한다.

이제 트레인을 시도하면 loss가 점점 줄어드는 것을 볼 수 있다. 예제에서는 20000번 동안 반복을 실행한다. 2만번 정도 실행하면 로스가 별로 안줄어 들기 때문에 2만번 정도로 실행한다. 보시는 것처럼 hidden layer에 있는 값 자체거 word vector인것을 확인할 수 있다.

word별로 2차원 벡터가 생성된 것을 볼 수 있다.

이를 차트에 나타내면 다음과 같다. king과 man이 상당히 비슷하고 boy와 prince가 비슷한 것을 알 수 있다. princess와 wise이 woman, girl, queen이 비슷하다.

이처럼 Word2Vec을 사용해서 전혀 유사도가 없었던 단어들을 유사도가 있는 벡터로 만들 수 있다. 유사도는 바로 문장에 있는 이웃들로 유사도를 측정한 것이다. 모든 단어들이 벡터 공간안에서 유사도를 가진 채로 있는 것을 확인할 수 있고 이 유사도가 있는 벡터로 이제 또 다른 nlp를 위한 딥러닝 모델도 만들어나갈 수 있다.
'DSCstudyNLP' 카테고리의 다른 글
[6주차] Youtube 허민석 : 딥러닝 자연어처리 (2차) (0) 2020.02.19 [6주차] 딥러닝 2단계 : 다중 클래스 분류/프로그래밍 프레임워크 소개 (0) 2020.02.17 [5주차] 딥러닝 2단계 : Batch Normalization (0) 2020.02.10 [5주차] 딥러닝 2단계 : 하이퍼파라미터 튜닝 (0) 2020.02.08 [4주차] 딥러닝 2단계 : 최적화 알고리즘 (0) 2020.02.05